Benchmarking GenAI Models for AM
This project presents a comprehensive methodology for evaluating the capabilities of various existing GenAI tools in addressing diverse AM-related tasks. The focus is on establishing qualitative metrics that can help you assess and compare different GenAI models for additive manufacturing applications.
Key Concepts:
- Evaluation Framework: A structured approach to assess GenAI performance in AM contexts
- Qualitative Metrics: 35 metrics across three categories to comprehensively evaluate model capabilities
- Scoring Matrix: A practical tool for assessing different GenAI models on AM-specific tasks
- Comparative Analysis: Methods to benchmark various GenAI tools against each other
Our research evaluated several major GenAI models including GPT-4, GPT-3.5, Gemini (previously BARD), Llama 2, DALL·E 3, and Stable Diffusion across a range of AM-specific tasks using these metrics.
Qualitative Metrics Framework
Our benchmarking framework is built around 35 qualitative metrics organized into three main categories. This comprehensive set of metrics allows for a detailed assessment of how well different GenAI models perform on AM-related tasks.
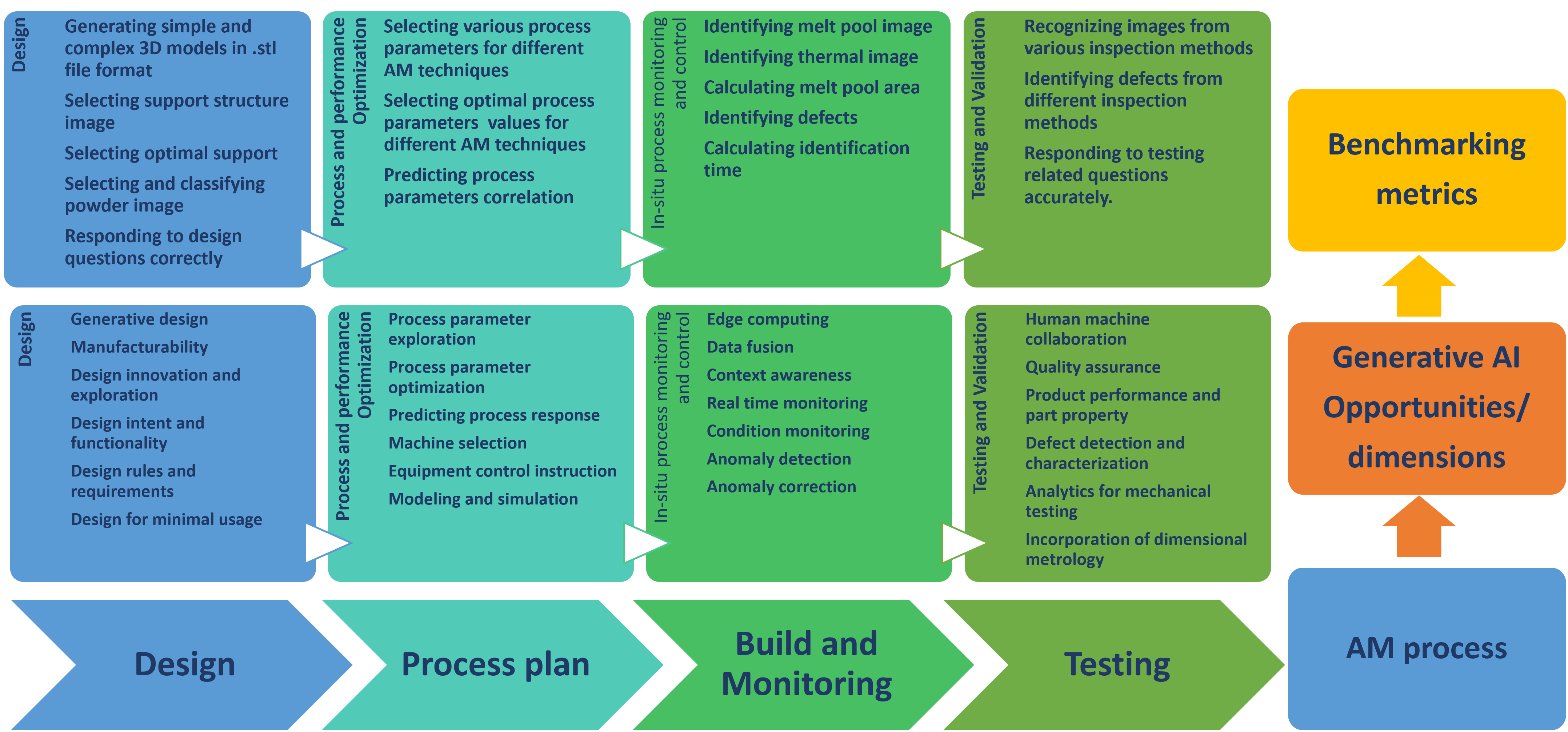
The three categories of qualitative metrics for evaluating GenAI models in AM
Metric Categories
The metrics are divided into three main categories, each addressing different aspects of GenAI performance:
Agnostic Metrics
General capabilities applicable across domains, including accuracy, coherence, and relevance.
Domain Task Metrics
Metrics specific to the additive manufacturing domain, such as AM knowledge and process understanding.
Problem Task Metrics
Metrics focused on specific AM problem types, like design generation, parameter optimization, and defect detection.
Source Code and Resources
For practical implementation of this benchmarking framework, you can access the following resources:
- GitHub Repository with implementation code and examples
- Standardized test queries for AM applications
- Sample scoring templates and evaluation protocols
Contribution
The wrok is a collaboration of Nowrin, Paul withrell, Vinay Saji, Soundar Kumara
Publication
If you are interested in the details, please refer to my following paper:
Current state and benchmarking of generative artificial intelligence for additive manufacturing, IDETC-CIE 2024.Learn More About GenAI Benchmarking
For more comprehensive understanding of benchmarking and evaluation, explore these related resources: